28.8h
课程时长18675人
学习人数24个月
课程有效期| 课程参数 | |
| 教学服务 |
|
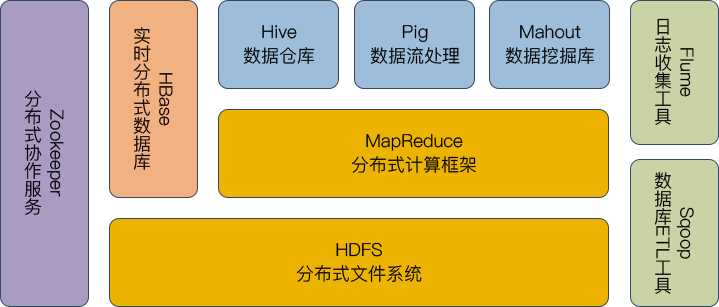
它能搭建大型数据仓库,PB级别数据的存储、处理、分析、统计等业务。
• 搜索引擎数据分析
• 海量日志分析【一般这个场景多】
• 商业智能【数据报表的呈现】
• 数据挖掘【沙子里淘金】
Hadoop旗下有很多经典子项目,比如HBase、Hive等,这些都是基于
HDFS和MapReduce发展出来的。
• HDFS: 为海量的数据提供了存储
• MapReduce:为海量的数据提供了计算
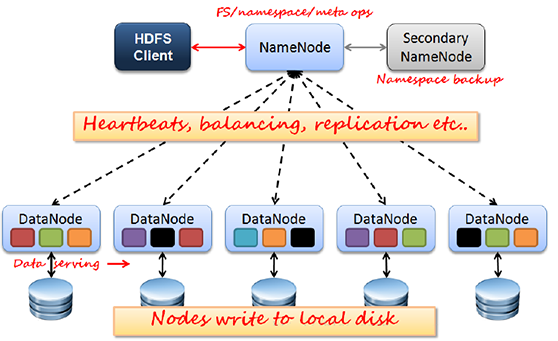
Client:切分文件;访问HDFS;与NameNode交互,获取文件位置信息;与DataNode交互,读取和写入数据。
NameNode:Master节点,在hadoop1.X中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户端请求。
DataNode:Slave节点,存储实际的数据,汇报存储信息给NameNode。
Secondary NameNode:辅助NameNode,分担其工作量;定期合并fsimage和fsedits,推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。

JobTracker:Master节点,只有一个,管理所有作业,作业/任务的监控、错误处理等;将任务分解成一系列任务,并分派给TaskTracker。
TaskTracker:Slave节点,运行Map Task和Reduce Task;并与JobTracker交互,汇报任务状态。
Map Task:解析每条数据记录,传递给用户编写的map(),并执行,将输出结果写入本地磁盘(如果为map-only作业,直接写入HDFS)。
educer Task:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行。
HDFS Client:进行文件的分块与文件的发送读取。
Namespace image:记录每个文件的存在位置信息。
Edit log:记录每个文件的位置移动信息。
Namenode(Master):
管理着每个文件中各个块所在的数据节点的位置信息。
Secondary Namenode:更新并备份Namenode。
Datanode(Slave):
记录着服务器内所储存的数据块的列表。
JobClient:
用于把用户的作业任务生成Job的运行包,并存放到HDFS中。
JobinProgress:
把Job运行包分解成MapTask和ReduceTask并存放于TaskTracker中。
JobTracker(Master):
进行调度管理TaskTracker执行任务。
TaskTracker(Slave):
执行分配下来的Map计算或Reduce计算任务

Hadoop是在可用的计算机集群间分配数据并完成计算任务的,这些集群可用方便的扩展到数以千计个节点中。

Hadoop通过普通廉价的机器组成服务器集群来分发以及处理数据,以至于成本很低。

通过并发数据,Hadoop可以在节点之间动态并行的移动数据,使得速度非常快。

能自动维护数据的多份复制,并且在任务失败后能自动地重新部署(redeploy)计算任务。所以Hado op的按位存储和处理数据的能力值得人们信赖。
架构专家
传授多年经验
系统学习
全程实战演练
班主任全程
陪伴监督学习
随时学习无需等待
学习时间灵活把握
检验巩固阶段学习效果
及时查漏补缺
班主任学习督导
确保学员进度
配套讲义、视频
等学习资料



