45.83h
课程时长11999人
学习人数24个月
课程有效期| 课程参数 | |
| 教学服务 |
|

Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所具有的优点,Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。Spark是Scala编写,方便快速编程。
Spark提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求。
知识体系完备,阶段学习者都能学有所获
综合各种方式演示代码、分析逻辑,生动形象,化繁为简,讲解通俗易懂
结合工作实践及分析应用,培养解决实际问题的能力
使用综合案例来加强重点知识,用切实的应用场景提升编程能力,充分巩固各个知识点的应用
整个课程的讲解思路是先提出问题,然后分析问题,并编程解决解题
包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core之上的
提供通过Apache Hive的SQL变体Hive查询语言(HiveQL)与Spark进行交互的API。每个数据库表被当做一个RDD,Spark SQL查询被转换为Spark操作。
对实时数据流进行处理和控制。Spark Streaming允许程序能够像普通RDD一样处理实时数据
一个常用机器学习算法库,算法被实现为对RDD的Spark操作。这个库包含可扩展的学习算法,比如分类、回归等需要对大量数据集进行迭代的操作。
控制图、并行图操作和计算的一组算法和工具的集合。GraphX扩展了RDD API,包含控制图、创建子图、访问路径上所有顶点的操作

SparkSQL:关系计算
SparkStreaming: 实时计算
Mllib:传统机器学习、迭代计算
GeaphX:图计算

Yarn、Kubernetes
Mesos、Standalone

HDFS、KafKa、Flume
HBase、Cassandra、Mongodb
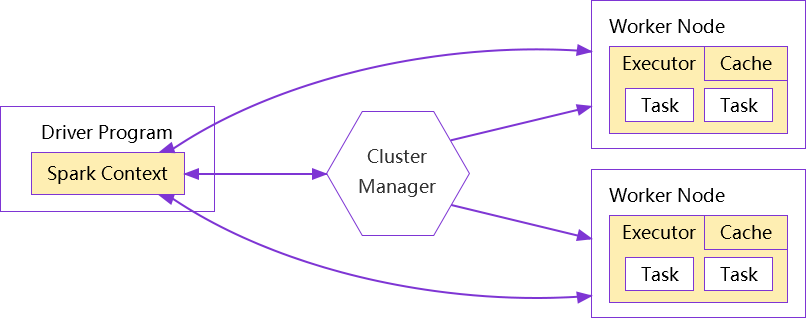
在standalone 模式中即为Master主节点,控制
整个集群,监控worker。在YARN模式中为
资源管理器
从节点,负责控制计算节点,启动Executor
或者Driver
一个Spark程序有一个Driver,一个Driver创建一个
SparkContext,程序的main函数运行在Driver中
负责解析Spark程序、划分Stage、调度任务到
Executor上执行
负责加载配置信息,初始化运行环境,创建
DAGScheduler和TaskScheduler
负责执行Driver分发的任务,一个节点可以
启动多个Executor,每个Executor通过多
线程运行多个任务
Spark运行的基本单位,一个Task负责处理
若干RDD分区的计算逻辑

掌握Hadoop及HDFS原理和使用

掌握MapReduce原理及代码编写

掌握Scala语言编程

掌握zookeeper、Hive、Hbase
原理及使用
架构专家
传授多年经验
系统学习
全程实战演练
班主任全程
陪伴监督学习
随时学习无需等待
学习时间灵活把握
检验巩固阶段学习效果
及时查漏补缺
班主任学习督导
确保学员进度
配套讲义、视频
等学习资料



