25.73h
课程时长17689人
学习人数24个月
课程有效期| 课程参数 | |
| 教学服务 |
|
1、数据除了从Fulme中来,也可能直接使用Kafka的producer角色往Kafka中直接生产数据
2、大数据实时计算系统,比如说用storm、spark streaming开发的,可以实时从Kafka中拉去数据、然后对实时的数据进行处理和计算,需要较为复杂的业务逻辑,甚至调用复杂的机器学习,数据挖掘,智能推荐的算法,从而实现车辆调度和实时推荐
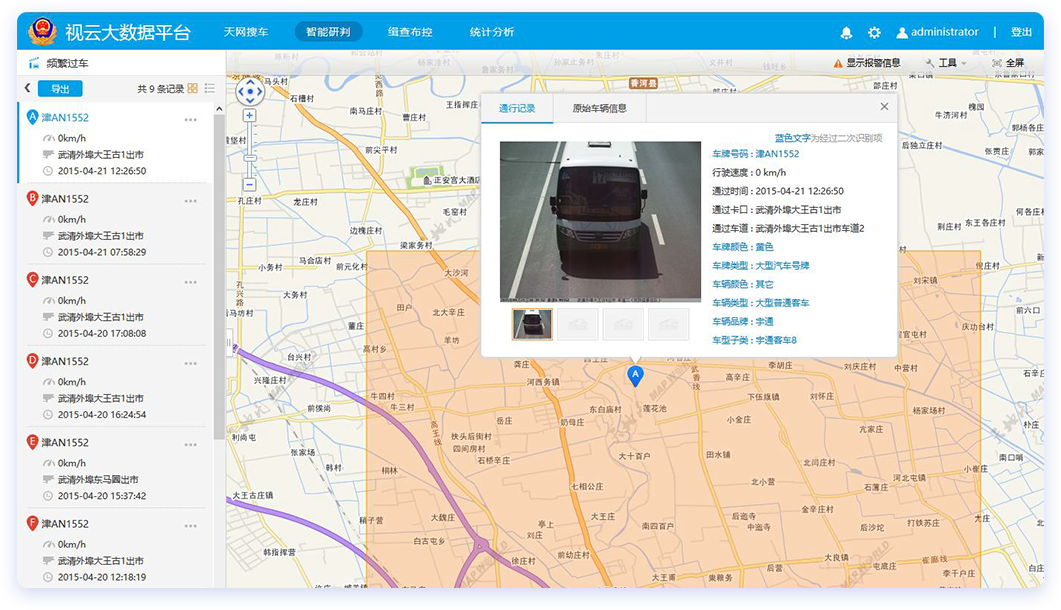
• 卡扣流量分析 Spark Core
• 卡扣流量分析 Spark Core
• 各区域车流量最高Top5 道路统计 SparkSQL
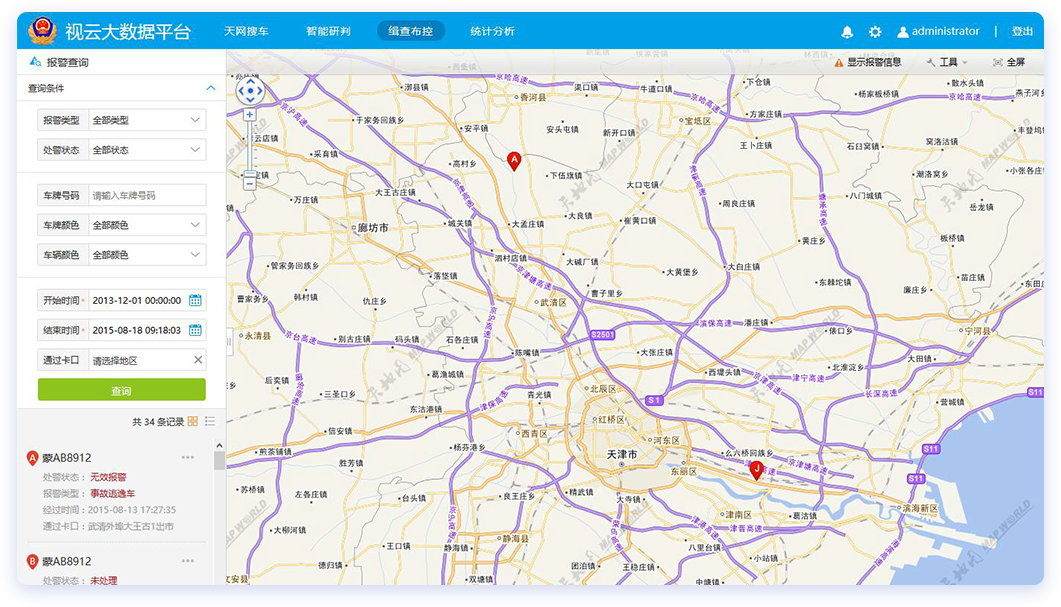
• 稽查布控,道路实时拥堵统计Spark Streaming
1、J2EE平台,前端页面,在页面中可以指定任务类型,提交任务的参数(比如时间范围、区域设计)
2、平台接受用户的提交请求,会调用底层封装的Spark—submit的shell脚本
3、运行的作业可以获取到用户指定的筛选条件,根据条件进行计算
4、Spark任务的计算会写入到数据库中,比如MySQL、Redis等
5、J2EE平台可以通过前端页面、展示结果(以表格和图标方式)
在智慧城市阶段,数字城市与物理城市可以通过物联网进行有机的融合,形成虚实一体化的空间(syber physical space)。在这个空间内,将自动和实时地感知现实世界中人和物的各种状态和变化,由云计算中心处理其中海量和复杂的计算与控制,为人类生存繁衍、经济发展、 社会交往等提供各种智能化的服务,从而建立一个低碳、绿色和可持续发展的城市。
城市中每时每刻都会产生海量数据,应用数据挖掘、机器学习和可视化技术,分析出的数据可以改进城市规划,缓解交通拥堵,抓捕罪犯。项目会使用真实的数据进行数据分析。

架构专家
传授多年经验
系统学习
全程实战演练
班主任全程
陪伴监督学习
随时学习无需等待
学习时间灵活把握
检验巩固阶段学习效果
及时查漏补缺
班主任学习督导
确保学员进度
配套讲义、视频
等学习资料



