这个和全量10000次计算次数是不是一样的呀
scikit-learn 里面的线性回归是不是比直接用求参公式要慢呀
老师, polynomial_features.fit_transform的结果是作为新的X给线性回归算法用, 我这样理解没错吧?
老师,这里说的非线性变化成线性是利用上升维的手段, 假如我有个非线性数据集如下:
首先第一个问题, 我判断这是非线性的数据集(因为维度貌似没啥关系,很有相互独立的感觉), 不知道这么判断对不对?
第二个问题, 我是不是得先运用升维手段, 把数据集变为线性的, 在更高维度作平面, 最后就可以利用上Ridge/Lasso算法去训练模型?
老师, 以MSE为例, 我们的惩罚项是在公式中什么位置?
1. W(t+1) = W(t) - alpha*g + 正则项?
2. W(t+1) = W(t) - alpha*g(Loss+正则项)?
如果是2的话, 那么常数的梯度不就是0了吗? 我有点不明白是作用在哪个位置。
另外, 这个惩罚项是不是对于不同的特征维度,也是可以给与不同的人为修正的呢? 有没有什么动态调整的原理(就像之前的视频里面学习率那样随着迭代次数增加而减少)?
老师, 如果数据集Xj列是属于稀疏性描述中偏疏的,也就是很多0, 加上其中有很大的离散值, 那么标准归一化会不会反而效果不大了? 或者说, 数据偏疏的话, 离散值对归一化效果的影响(权重)也会相对较大?
老师, 视频里面创建数据的时候, y = 4 + 3*X + np.random.randn(100,1), 我知道截距项是4和系数是3。对于在实际的数据集, 我们怎么才能知道它的截距项和对应Xj的系数是什么? 当然, 同时我也想问问我们怎么能确定我们的数据适用于多元线性回归? 因为只有知道数据适用于什么公式,然后才能选择对应算法和它的损失函数求梯度。
老师,我有几个问题想问问。
Q1. 视频中提及要每个维度下降逼近而得出最优解。那么,因为每个维度的路线是不一样的(学习率一样),那就会出现不同步的现象?也就是有些维度可能很快就得出最优解了,但有些还没有,,而程序还在继续迭代,在学习率也是一致的情况下,那么对于已经是最优解得维度会不会调过调飞了?
Q2. 如果会的话,我们怎么可以做到某一个维度的点到即止?
Q3. 如果做不到的话,那么是不是说,我们是看整体参数的效果?也就是,可能W0,W1,W3是最优但W2不需要最优,我们不断地去测试中间输出的参数组合,看看能不能满足需求(实际上可能几个组合的准确率都能达到业务需求,譬如:W0,W1,W4是最优而W3不是最优)。
老师, 我有点不明白。 样本X矩阵映射到三维空间, 那凸还是非凸很多时候取决于样本间特征维度? 如果是, 我大概能想象工作上的数据集很多时候都可能出现非凸的情况, 那这样可不可以说其实解析解几乎用不上?我这么理解或者总结对不对? 此外, 视频里面提到,机器学习基本都用凸函数去计算, 这句话怎么说得那么肯定, 不是应该取决于数据集吗?
老师,我看前面MLE视频和MSE推导的公式好像有点不一样,不太明白这点。MLE那里是1/root(2*pi*sigma^2), 但是求导公式这里却是以下的样子, 就是sigma的位置和平方也不见了。
2021-03-08.png
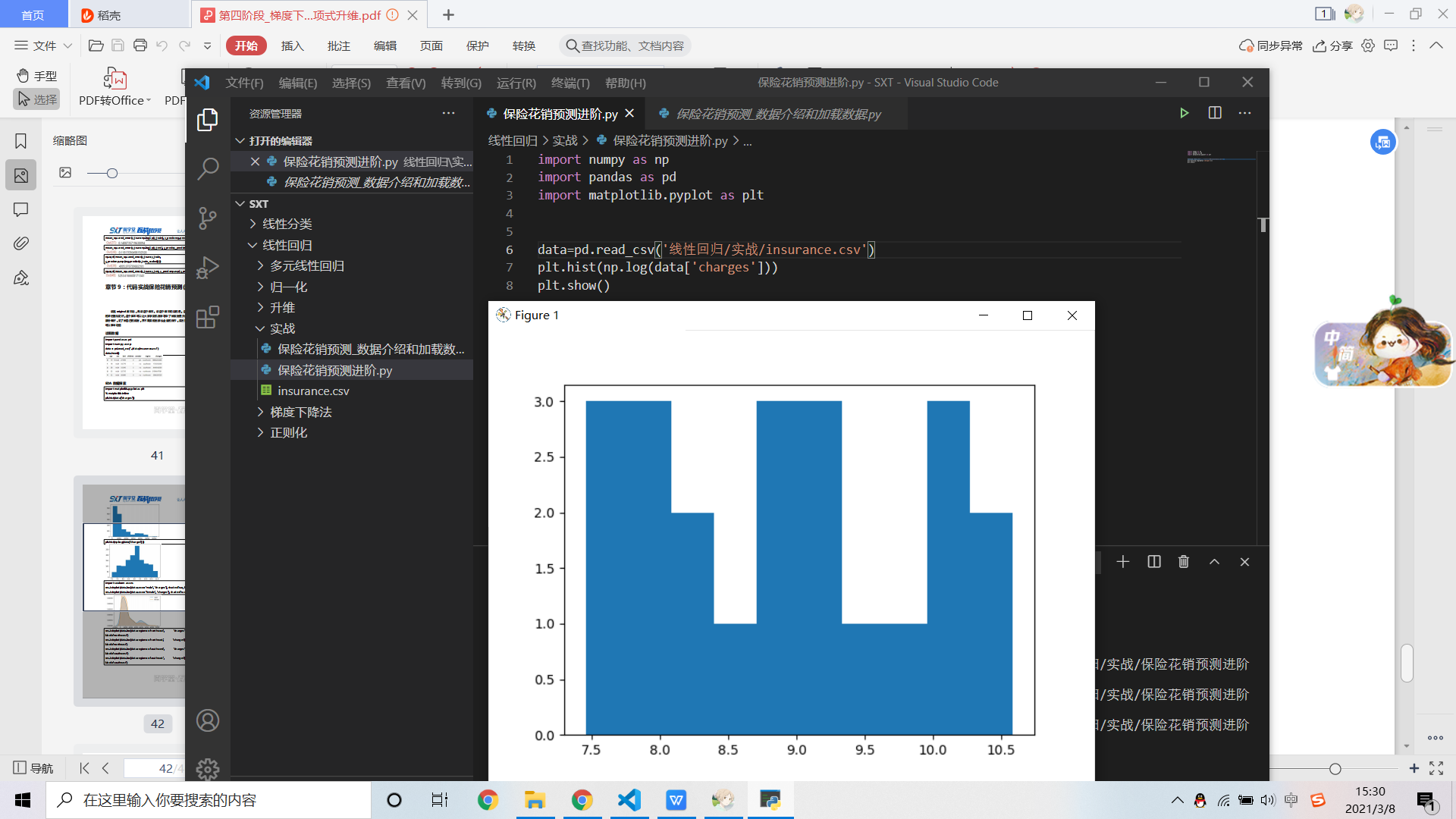
老师 为什么会出现这种情况
老师,加上惩罚项之后,是怎么降低降低模型在训练集上的正确率的?
老师 这里第二个for循环意义是什么呢?随机梯度下降不是一个批次一次迭代吗
老师,我们是已知y的值才用解析解求出θ参数,视频里已经的y为什么是根据公式随机出来的呢?而且根据y的公式不是已知W参数了吗,为什么还要再求一次呢?
老师我这样理解对吗?已知n个样本→求出哪个模型最有可能得到这n个样本→根据最大似然函数求出估计量→把估计量带回原模型
非常抱歉给您带来不好的体验!为了更深入的了解您的学习情况以及遇到的问题,您可以直接拨打投诉热线:
我们将在第一时间处理好您的问题!
关于
课程分类
百战未来微信公众号
百战未来微信小程序
©2014-2026百战汇智(北京)科技有限公司 All Rights Reserved 北京亦庄经济开发区科创十四街 赛蒂国际工业园网站维护:百战汇智(北京)科技有限公司 京公网安备 11011402011233号 京ICP备18060230号-3 营业执照 经营许可证:京B2-20212637





{kind=link}