2021-03-08.png
老师 为什么会出现这种情况
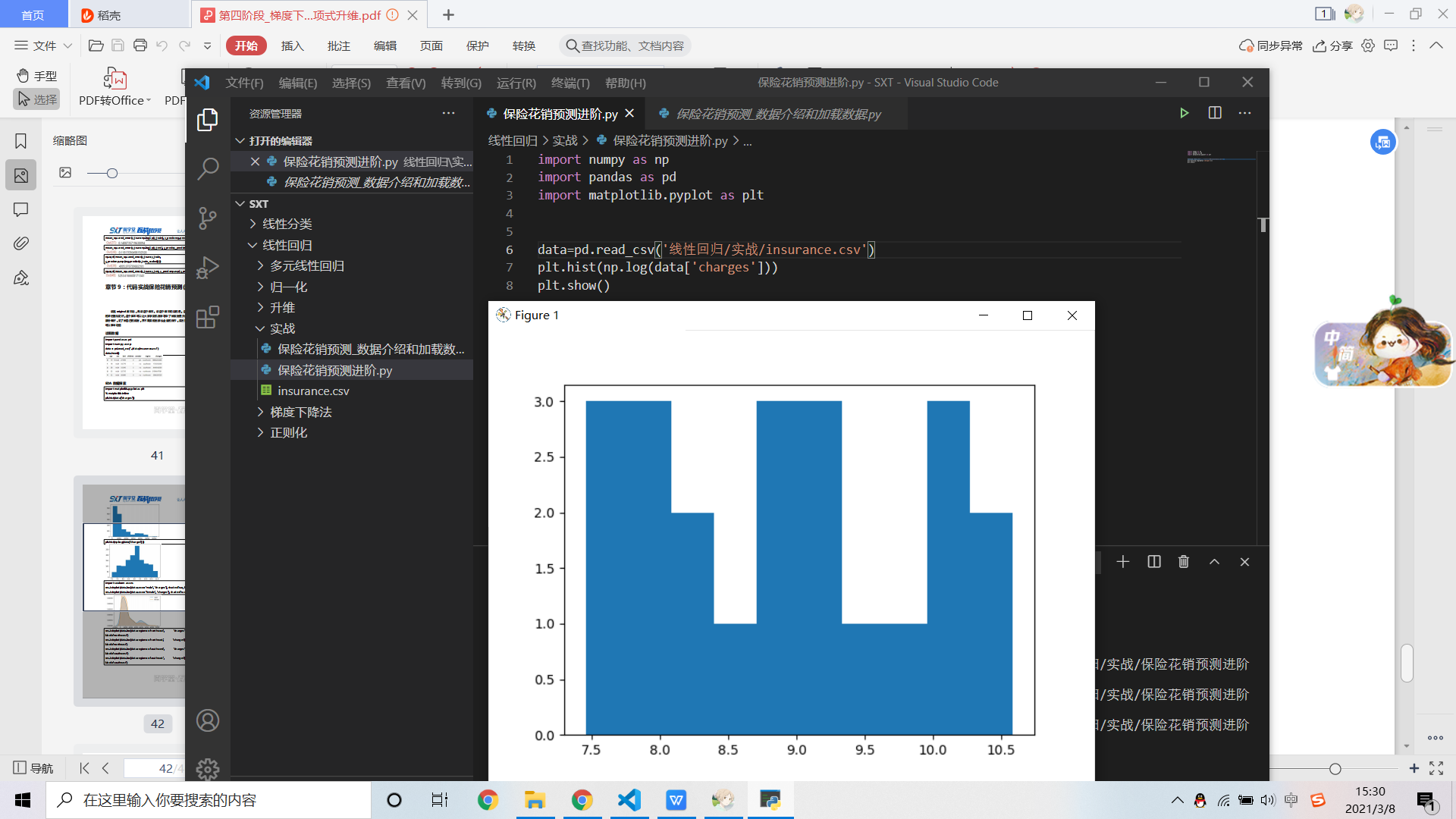
这里为啥加个log就可以使数据服从正态分布啊,是有什么数学依据吗
还有就是对于线性回归我们不是假设数据的误差服从正态分布么,这个和数据本身服从正态分布有区别吗
老师 如何判断某一个参数此时达到最优呢?
老师你好,请教一下这个小节里提到的y、X1和X2是否一定两两正交?如果是两两正交的话,那么他们是否一定相互独立?
老师你好,请教一下这个小节里提到的y、X1和X2是否一定要两两正交?如果是两两正交的话,那么他们是否一定相互独立?
老师 为啥可以写成 W的转置 * X 啊,什么情况下可以把 X矩阵当作 向量处理啊。
numpy np matplotlib.pyplot plt sklearn.linear_model LinearRegression x1 = *np.random.rand() x2 = *np.random.rand() x3 = *np.random.rand() X = np.c_[x1x2x3] y = + *x1 +*x2+*x3+ np.random.randn() reg = LinearRegression(=) reg.fit(Xy) (reg.intercept_reg.coef_) X_new = np.array([[][][]]) y_predict = reg.predict(X_new) plt.plot(X_new[:]y_predict) plt.plot(x3y) plt.axis([]) plt.show()
预测的不hi是很好啊???
“通常标准归一化中包含了均值归一化和方差归一化。经过处理的数据符合标准正态分布,即均值为0,标准差为1”。 这句话是不是有瑕疵呀,若原来未经标准归一化的数据本身不服从正太分布,经过标准归一化处理的数据应该也不会服从标准正太分布的。
为什么说L2 每次多走的幅度是之前的 2 倍的 t时刻的Wi呢,根据公式每次多更新的幅度不应该是学习率乘以Wi吗
数据处理的时候,品状数据图 怎么矫正 成正太分布啊?
老师,不知道我这样理解对不对。
因为误差 = y-y_hat, 所以误差和y之间是有关系的,也就是跟我们想要求的模型(beta/w)是相关的。而我们假设了每个样本对应的误差为正态分布,所以当我们求出了所有样本误差对应概率的最大似然,其对应的theta就是我们要的模型theta*,而这个模型也等同于回归想要求出的模型。
老师我想问下,因为小批量梯度下降在选择batch的时候是完全随机的。也就是说,无论如何循环,我都是每次在大的样本集里面选择随机10个样本。那这个一次循环之后再用num_batches二次循环的意义是什么呢?
请问老师,对于一元线性回归的最大似然估计可不可以理解为:
模型的组测输出公式为y^= wx + b, 和真实值的误差是e,所以真实值y和预测值y^之间的关系可以定为:
y = y^ +e = wx +b +e。 所以当误差e最小时所对应的w和b就是我们需要的模型最佳参数。
因为e是符合正态分布,那么y也是符合正态分布的。所以y可以写成关于w和b的符合正态分布的概率密度公式。其中均值是wx + b,方差是一个常熟。那么对于一个样本,当这个概率密度最大的时候也就是wx + b越接近y的时候,我们模型的预测是最准确的,得到真实值的概率是最大的。此时所对应的w参数wb就是我们需要的模型参数。
因为我们所有样本都满足独立分布,所以总概率就可以写成所有样本的上述概率密度的累乘,我们只要最大化这个累乘后的概率密度,就可以找到对于所有数据样本来说最接近真实y概率的对应参数wb从而得到一个拟合不错的线性模型。
之后两边同取对数之后,因为以e为底的对数函数是单调递增的,所以最大化似然函数等同于最大化这个对数函数。因为化简后有一个常数项和一个有负号的关于wb的一项,那么问题就变成了最小化去掉负号的带有wb的这一项函数,从而就推导出来了我们的mse损失函数。
我有点不太明白,Jacobi和Hessian矩阵是采用分子布局的,在计算中采用分母布局的方法求导,而且Jacobi、Hessian是用于判定计算结果的凸性的,这样不会有什么问题吗?
老师可以解释一下什么是解释型语言,什么是编译型语言吗。本质区别是什么?
非常抱歉给您带来不好的体验!为了更深入的了解您的学习情况以及遇到的问题,您可以直接拨打投诉热线:
我们将在第一时间处理好您的问题!
关于
课程分类
百战未来微信公众号
百战未来微信小程序
©2014-2026百战汇智(北京)科技有限公司 All Rights Reserved 北京亦庄经济开发区科创十四街 赛蒂国际工业园网站维护:百战汇智(北京)科技有限公司 京公网安备 11011402011233号 京ICP备18060230号-3 营业执照 经营许可证:京B2-20212637



![(AU9J6%]9Y1VCD~NWN7{CMO.png](/ueditor/php/upload/image/20220924/1663986958956389.png "1663986958956389.png")




{kind=link}