docker run --name mytomcat -p 8080:8080 -v /opt/webapps:/usr/local/tomcat/webapps -d tomcat
我执行之后 查看了docker ps 发现没有运行
from urllib.request import urlopen,Request from urllib.parse import quote #报错 #UnicodeEncodeError: 'ascii' codec can't encode characters in position 16-17: ordinal not in range(128) # #url里面的参数不能为中文 args = 'python' url = f'https://www.baidu.com/s?wd={quote(args)}' header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36'} req = Request(url,headers=header) resp = urlopen(req) print(resp.read().decode()[:1500])
老师帮我看下哪里错了
这章只能看到7分多就会直接跳下一章了
为什么我的vscode不会弹出这行灰色的提示(options=options),要怎么弄出来
scrapy03.zip
老师,我写的只能爬取到第一页的数据,第二页的数据就显示读取不到了
代码和视频的都一模一样,访问页成功了,返回的是200,xpath路径页没有错,但是为什么获取不到图片的地址啊
老师,我的vscode终端都不能运行scrapy,但是cmd窗口是可以运行的,这是为啥呀?
SDKmanager卡住了
老师,macOS下载夜神模拟器后没有夜神多开器,要怎么安装安卓5呢
scrapyd当爬虫代码修改了需要停止爬虫然后重新部署吗
老师你好:
请问老师这个红框里面的是啥意思?
这里每次运行request一次就会自动扣费吗
db.xinchun.find({$where: () => this.name==='zs'})
db.xinchun.find({$where: function(){return this.name==='zs'}})
为什么这里能使用箭头函数的语法却无法生效,还是我写错了
scrapy指令执行错乱
这个问题没有任何的报错,scrapy也能正常运行,但是就算有问题:
本人在scrapy项目里面创建好一个.py文件,且正常爬取到网站之后,当在该项目下终端运行指令scrapy相关指令(如scrapy crawl、scrapy genspider --)结果都执行的是我前面创建好的.py文件的运行效果,尽管我的指令明明是创建文件甚至指令都不全面,重启项目、重装scrapy、更换编辑器、都没能解决,创建一个新项目能正常执行genspider指令,但是同样只能创建一个,再次创建就是craw的效果了
非常抱歉给您带来不好的体验!为了更深入的了解您的学习情况以及遇到的问题,您可以直接拨打投诉热线:
我们将在第一时间处理好您的问题!
关于
课程分类
百战未来微信公众号
百战未来微信小程序
©2014-2026百战汇智(北京)科技有限公司 All Rights Reserved 北京亦庄经济开发区科创十四街 赛蒂国际工业园网站维护:百战汇智(北京)科技有限公司 京公网安备 11011402011233号 京ICP备18060230号-3 营业执照 经营许可证:京B2-20212637



 为什么我的vscode不会弹出这行灰色的提示(options=options),要怎么弄出来
为什么我的vscode不会弹出这行灰色的提示(options=options),要怎么弄出来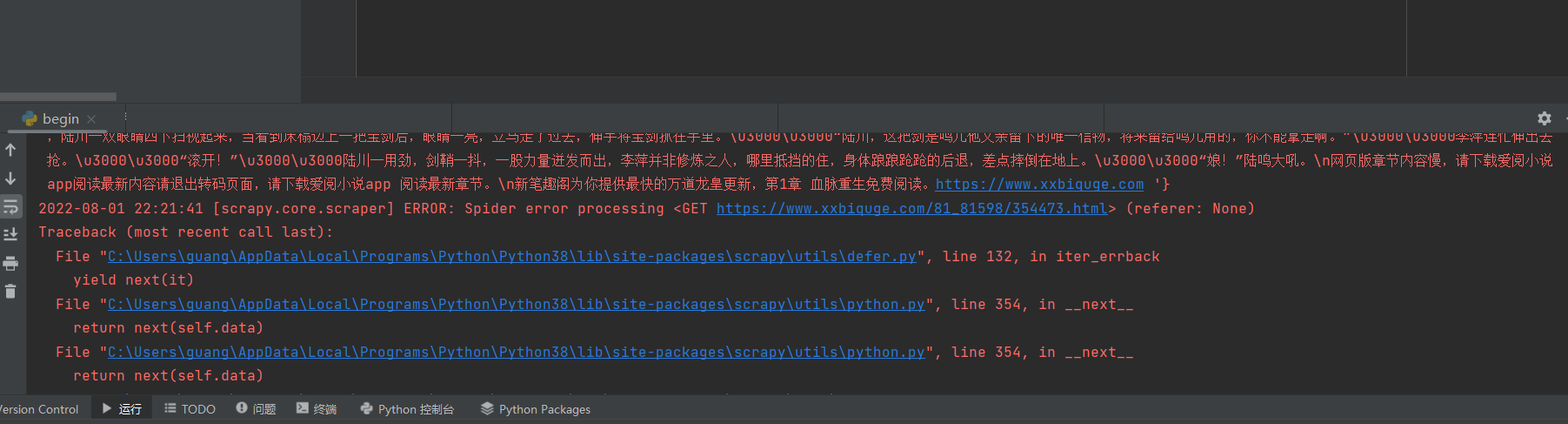

 代码和视频的都一模一样,访问页成功了,返回的是200,xpath路径页没有错,但是为什么获取不到图片的地址啊
代码和视频的都一模一样,访问页成功了,返回的是200,xpath路径页没有错,但是为什么获取不到图片的地址啊
 SDKmanager卡住了
SDKmanager卡住了

