import execjs
# 读取js代码
with open('./爬虫与反爬/16js.js','r') as f:
js_code = f.read()
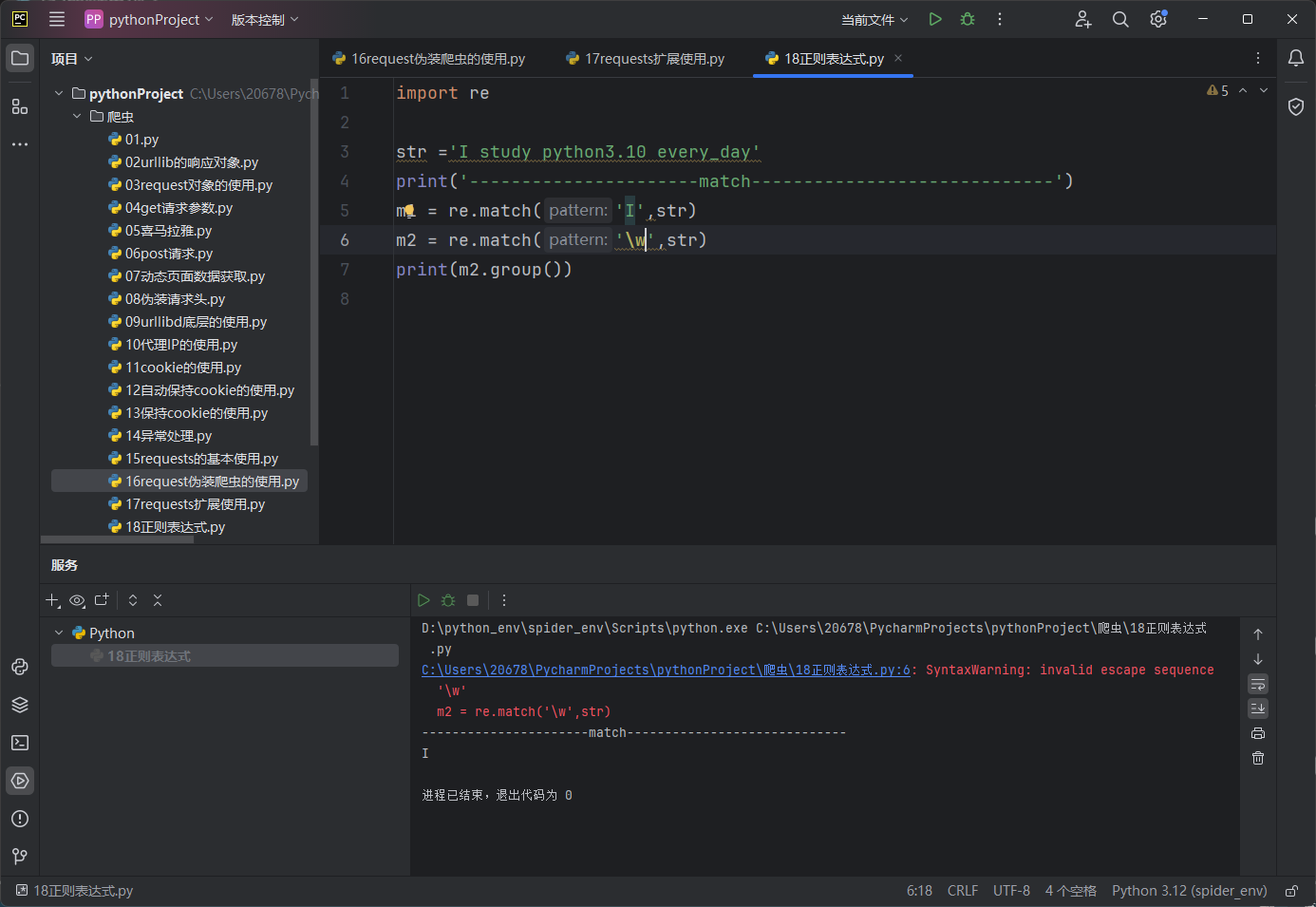
# 解析js,创建js对象
ctx = execjs.compile(js_code)
t = "MZphJmFlelDpw2aSCfdFb/P3tx6u8VHU/M7MqPRS6y6RaH/5IbXivLEiR9o33DJkTcSPLypQCFpPR82kvps4XAS/QiDAsPVBMK4HU3LUuLyxQLn42XoQKtsRU3nLrOppUcsUCaY8vfPxRtOB4RmS8utPv1yghJtEXPzFsqCxHdcMCUo/o0DpzF5NzSMvlvmYDctx2SVncj3BldMoJn2SZLwPyk2NghU08KyffZyPMaiTmaAeX42LAu8//RhilPgFkR4WUfSd2JSf5WLW1LG0xNJQXx0V1mwtdekmdeH1VkFuapV7vq+eUWCydb4g4fzb+gAwJL8FCmRzBol9j8tdr3ikRFVEttwRl9PG7/ihq/YjCAvWr4S4BAHs4ZRtfo3RMCYFHi+jPkAJWSDArZGriI069tqw9zN04c5G6N4DVQSHwOvm0/JnTWjrIJ/7YTGM+e6lE0DCglS3dHuwxQEGYp3tfxIqnuEMZglV+8rpeVwPoZcWzE3A+0zqJ1ypmhsLk6ZKqpp1jnwvnzCyc3XEvvNlC++1BOPDxaBjjWc94/mcXO37RwjEVQx/h6sCIRJzo9Qwpe2emcsK/ZvAN2433cXPrdZXn1RTWnYkI/NfUMAfib+W54hkccA1krMstvc3oahDlYhOlTlv2OmGoknLoBaWnXiU3Dv51apgdZ4XBpBfN4HOzY12/zq4cnd1u319dBu0fRETiadFXqAUE9nRbmqZtQ4L7/byasPdOOxOagv7nIH4bvcXpfXDqhz6CMDL9Ei+N/dyRWlt3BX/bUPQ6H9E89HbmeJqJFPXZ1HeSHR2Ijl601S2B03lYQcrysSwWh8kzM1D/0N3Dm5z1R3kxvJ5iYpjfPBZH6ozU/4F4E42z1BInZRHViDc79MM6yNB433MMaAl5jsQBSDy33gBwlmx21J35xzmHdsLjmCuVstWvzWgVYOrRCD3dChIoueE"
params1= 'EB444973714E4A40876CE66BE45D5930'
params2 = 'B5A8904209931867'
# 调用js里的函数
rs = ctx.call('get_rs',t,params1,params2)
print(rs)老师我运行这个py文件报错是:
Traceback (most recent call last):
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.10_3.10.3056.0_x64__qbz5n2kfra8p0\lib\threading.py", line 1016, in _bootstrap_inner
self.run()
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.10_3.10.3056.0_x64__qbz5n2kfra8p0\lib\threading.py", line 953, in run
self._target(*self._args, **self._kwargs)
File "C:\Program Files\WindowsApps\PythonSoftwareFoundation.Python.3.10_3.10.3056.0_x64__qbz5n2kfra8p0\lib\subprocess.py", line 1515, in _readerthread
buffer.append(fh.read())
UnicodeDecodeError: 'gbk' codec can't decode byte 0x81 in position 189: illegal multibyte sequence
Traceback (most recent call last):
File "d:\spider\spider_code\爬虫与反爬\16_js破解.py", line 16, in <module>
rs = ctx.call('get_rs',t,params1,params2)
File "C:\Users\zzzzzzzbw\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\execjs\_abstract_runtime_context.py", line 37, in call
return self._call(name, *args)
File "C:\Users\zzzzzzzbw\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\execjs\_external_runtime.py", line 92, in _call
return self._eval("{identifier}.apply(this, {args})".format(identifier=identifier, args=args))
File "C:\Users\zzzzzzzbw\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\execjs\_external_runtime.py", line 78, in _eval
return self.exec_(code)
File "C:\Users\zzzzzzzbw\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\execjs\_abstract_runtime_context.py", line 18, in exec_
return self._exec_(source)
File "C:\Users\zzzzzzzbw\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\execjs\_external_runtime.py", line 88, in _exec_
return self._extract_result(output)
File "C:\Users\zzzzzzzbw\AppData\Local\Packages\PythonSoftwareFoundation.Python.3.10_qbz5n2kfra8p0\LocalCache\local-packages\Python310\site-packages\execjs\_external_runtime.py", line 156, in _extract_result
output = output.replace("\r\n", "\n").replace("\r", "\n")
AttributeError: 'NoneType' object has no attribute 'replace'


![8]CCLR_%J[]69V)BY$}3QS4.png](/ueditor/php/upload/image/20200403/1585897475768352.png "1585897475768352.png")











{kind=link}