老师,视频中的文档没有?视频老师的文档是《Docker技术应用开发实战》
老师,为什么我这样弄出来是空的
老师为啥我set·add. url的时候提示我不可哈希的list,
老师,这个地方为什么要采用[]将image_url括起来
我通过
pip3 install fake-useragent
下载fake-useragent库的时候一直提示我:error: could not create 'c:\program files\python37\Lib\site-packages\fake_useragent': 拒绝访问。
代码可以运行,但结果没出来中文
他把图片写到了js里面怎么整
2024-07-14 14:28:22 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2024-07-14 14:28:22 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2024-07-14 14:28:22 [scrapy.core.engine] DEBUG: Crawled (418) <GET https://bj.lianjia.com/ershoufang/> (referer: None)
2024-07-14 14:28:23 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <418 https://bj.lianjia.com/ershoufang/>: HTTP status code is not handled or not allowed
老师这是什么意思
老师,您这个视频比音频快了5秒以上,这也太有压了吧
如果某些网址需要登陆之后才能进行下一步,那对应的cookie应该怎么放进去,在哪个位置
# _*_coding=utf-8 _*_ from time import sleep import requests from fake_useragent import UserAgent from selenium import webdriver from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.support import expected_conditions as ec from selenium.webdriver.common.by import By from huadong import distance, track def save_img(): url = 'https://www.sf-express.com/cn/sc/dynamic_function/waybill/#search/bill-number/SF1406050054883' chrome = webdriver.Chrome() chrome.get(url) wait = WebDriverWait(chrome, 5) try: wait.until(ec.presence_of_element_located((By.ID, 'tcaptcha_popup'))) # 切换窗口 chrome.switch_to_frame('tcaptcha_popup') # 获取图片 img = chrome.find_element_by_id('slideBkg') img_src = img.get_attribute('src')[:-1] # 下载图片 download_img(img_src + '1', 'ctp1.png') download_img(img_src + '2', 'ctp2.png') # 获取滑动的距离 tmp_distance = distance.get_long() # 生成滑动轨迹 tk = track.get_track(tmp_distance-12) # 滑动按钮 # 选中按钮 button = chrome.find_element_by_id('tcaptcha_drag_button') webdriver.ActionChains(chrome).click_and_hold(button).perform() # 按轨迹滑动按钮 for t in tk: webdriver.ActionChains(chrome).move_by_offset(xoffset=t,yoffset=0).perform() # 释放按钮 webdriver.ActionChains(chrome).release().perform() # 休眠2秒 sleep(2) chrome.quit() except Exception as e: print(e) chrome.quit() def download_img(url, filename): # print(url) headers = { 'User-Agent': UserAgent().chrome } resp = requests.get(url, headers=headers) with open(f'./imgs/{filename}', 'wb') as f: f.write(resp.content) if __name__ == '__main__': save_img()
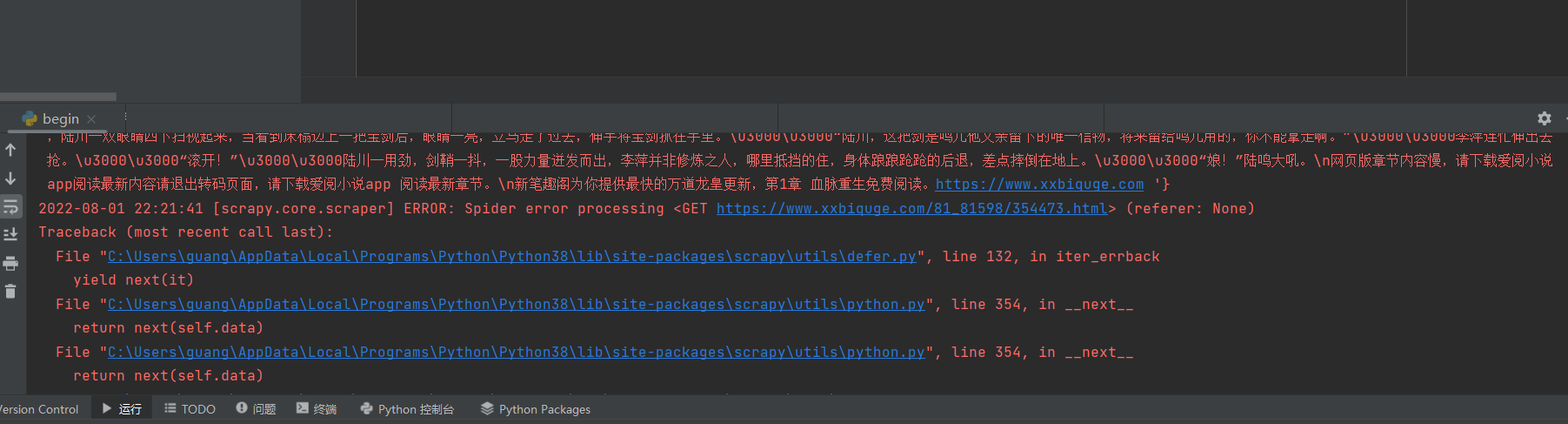
老师为啥报这个错误,,路径啥的都对啊
这一部分没有.md文档啊~~~~~~~~~
设置完IP后,模拟器报网络连接问题。
重启fiddler就可以了
最后并没有执行打印出 this is tomcat,看下怎么回事,打印的是1 4 16,是什么意思。这老师讲课太马虎了,都不讲明白
scrapy03.zip
老师,我写的只能爬取到第一页的数据,第二页的数据就显示读取不到了
非常抱歉给您带来不好的体验!为了更深入的了解您的学习情况以及遇到的问题,您可以直接拨打投诉热线:
我们将在第一时间处理好您的问题!
关于
课程分类
百战未来微信公众号
百战未来微信小程序
©2014-2026百战汇智(北京)科技有限公司 All Rights Reserved 北京亦庄经济开发区科创十四街 赛蒂国际工业园网站维护:百战汇智(北京)科技有限公司 京公网安备 11011402011233号 京ICP备18060230号-3 营业执照 经营许可证:京B2-20212637



 老师,这个地方为什么要采用[]将image_url括起来
老师,这个地方为什么要采用[]将image_url括起来