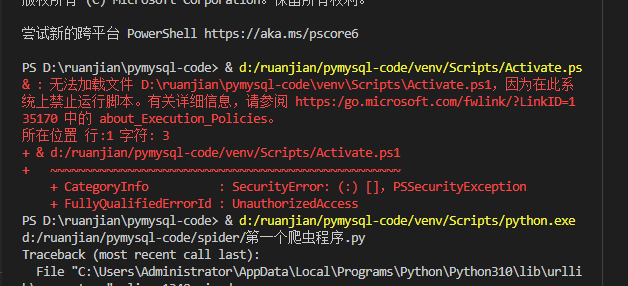
老师,我这个是?
PS D:\vscodeproject2\爬虫\Scarpy\scarpy05> & D:/python_env/spider2_env_/Scripts/Activate.ps1
(spider2_env_) PS D:\vscodeproject2\爬虫\Scarpy\scarpy05> & D:/python_env/spider2_env_/Scripts/python.exe d:/vscodeproject2/爬虫/Scarpy/scarpy05/scarpy05/begin.py
2023-12-26 22:01:30 [scrapy.utils.log] INFO: Scrapy 2.6.1 started (bot: scarpy05)
2023-12-26 22:01:30 [scrapy.utils.log] INFO: Versions: lxml 4.8.0.0, libxml2 2.9.12, cssselect 1.1.0, parsel 1.6.0, w3lib 1.22.0, Twisted 22.4.0, Python 3.10.0 (tags/v3.10.0:b494f59, Oct 4 2021, 19:00:18) [MSC v.1929 64 bit (AMD64)], pyOpenSSL 22.0.0 (OpenSSL 1.1.1n 15 Mar 2022), cryptography 36.0.2, Platform Windows-10-10.0.19045-SP0
2023-12-26 22:01:30 [scrapy.crawler] INFO: Overridden settings:
{'BOT_NAME': 'scarpy05',
'NEWSPIDER_MODULE': 'scarpy05.spiders',
'SPIDER_MODULES': ['scarpy05.spiders']}
2023-12-26 22:01:30 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2023-12-26 22:01:30 [scrapy.extensions.telnet] INFO: Telnet Password: 2e9c559873783f27
2023-12-26 22:01:30 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2023-12-26 22:01:30 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2023-12-26 22:01:30 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
Unhandled error in Deferred:
2023-12-26 22:01:30 [twisted] CRITICAL: Unhandled error in Deferred:
Traceback (most recent call last):
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\crawler.py", line 206, in crawl
return self._crawl(crawler, *args, **kwargs)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\crawler.py", line 210, in _crawl
d = crawler.crawl(*args, **kwargs)
File "D:\python_env\spider2_env_\lib\site-packages\twisted\internet\defer.py", line 1905, in unwindGenerator
return _cancellableInlineCallbacks(gen)
File "D:\python_env\spider2_env_\lib\site-packages\twisted\internet\defer.py", line 1815, in _cancellableInlineCallbacks
_inlineCallbacks(None, gen, status)
--- <exception caught here> ---
File "D:\python_env\spider2_env_\lib\site-packages\twisted\internet\defer.py", line 1660, in _inlineCallbacks
result = current_context.run(gen.send, result)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\crawler.py", line 102, in crawl
self.engine = self._create_engine()
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\crawler.py", line 116, in _create_engine
return ExecutionEngine(self, lambda _: self.stop())
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\core\engine.py", line 84, in __init__
self.scraper = Scraper(crawler)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\core\scraper.py", line 75, in __init__
self.itemproc = itemproc_cls.from_crawler(crawler)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\middleware.py", line 59, in from_crawler
return cls.from_settings(crawler.settings, crawler)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\middleware.py", line 41, in from_settings
mw = create_instance(mwcls, settings, crawler)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\utils\misc.py", line 166, in create_instance
instance = objcls.from_crawler(crawler, *args, **kwargs)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\pipelines\media.py", line 76, in from_crawler
pipe = cls.from_settings(crawler.settings)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\pipelines\images.py", line 112, in from_settings
return cls(store_uri, settings=settings)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\pipelines\images.py", line 55, in __init__
super().__init__(store_uri, settings=settings, download_func=download_func)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\pipelines\files.py", line 329, in __init__
self.store = self._get_store(store_uri)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\pipelines\files.py", line 378, in _get_store
store_cls = self.STORE_SCHEMES[scheme]
builtins.KeyError: 'd'
2023-12-26 22:01:30 [twisted] CRITICAL:
Traceback (most recent call last):
File "D:\python_env\spider2_env_\lib\site-packages\twisted\internet\defer.py", line 1660, in _inlineCallbacks
result = current_context.run(gen.send, result)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\crawler.py", line 102, in crawl
self.engine = self._create_engine()
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\crawler.py", line 116, in _create_engine
return ExecutionEngine(self, lambda _: self.stop())
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\core\engine.py", line 84, in __init__
self.scraper = Scraper(crawler)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\core\scraper.py", line 75, in __init__
self.itemproc = itemproc_cls.from_crawler(crawler)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\middleware.py", line 59, in from_crawler
return cls.from_settings(crawler.settings, crawler)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\middleware.py", line 41, in from_settings
mw = create_instance(mwcls, settings, crawler)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\utils\misc.py", line 166, in create_instance
instance = objcls.from_crawler(crawler, *args, **kwargs)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\pipelines\media.py", line 76, in from_crawler
pipe = cls.from_settings(crawler.settings)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\pipelines\images.py", line 112, in from_settings
return cls(store_uri, settings=settings)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\pipelines\images.py", line 55, in __init__
super().__init__(store_uri, settings=settings, download_func=download_func)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\pipelines\files.py", line 329, in __init__
self.store = self._get_store(store_uri)
File "D:\python_env\spider2_env_\lib\site-packages\scrapy\pipelines\files.py", line 378, in _get_store
store_cls = self.STORE_SCHEMES[scheme]
KeyError: 'd'
(spider2_env_) PS D:\vscodeproject2\爬虫\Scarpy\scarpy05>

 老师安装这个scrapy模块总是报错安装不成功怎么办
老师安装这个scrapy模块总是报错安装不成功怎么办






{kind=link}