session 设置盐 是什么意思
game.rar
爆炸效果报错,请帮我指点?
为什么第一行要写
#coding=utf-8
老师,请问我想将打印的爱你一百遍每打印出一次“爱你一百遍”就换行,怎么操作呢?
li=[]
for i in range(100):
li.append("爱你一百遍")
a=" ".join(li)
print(a)
老师,想问一下软连接的作用是啥,是类似把前一个访问地址重定向到后一个么,那它是一次定义就能永久使用嘛
老师,我更换文件夹打开代码之后就会出现这个,应该如何解决
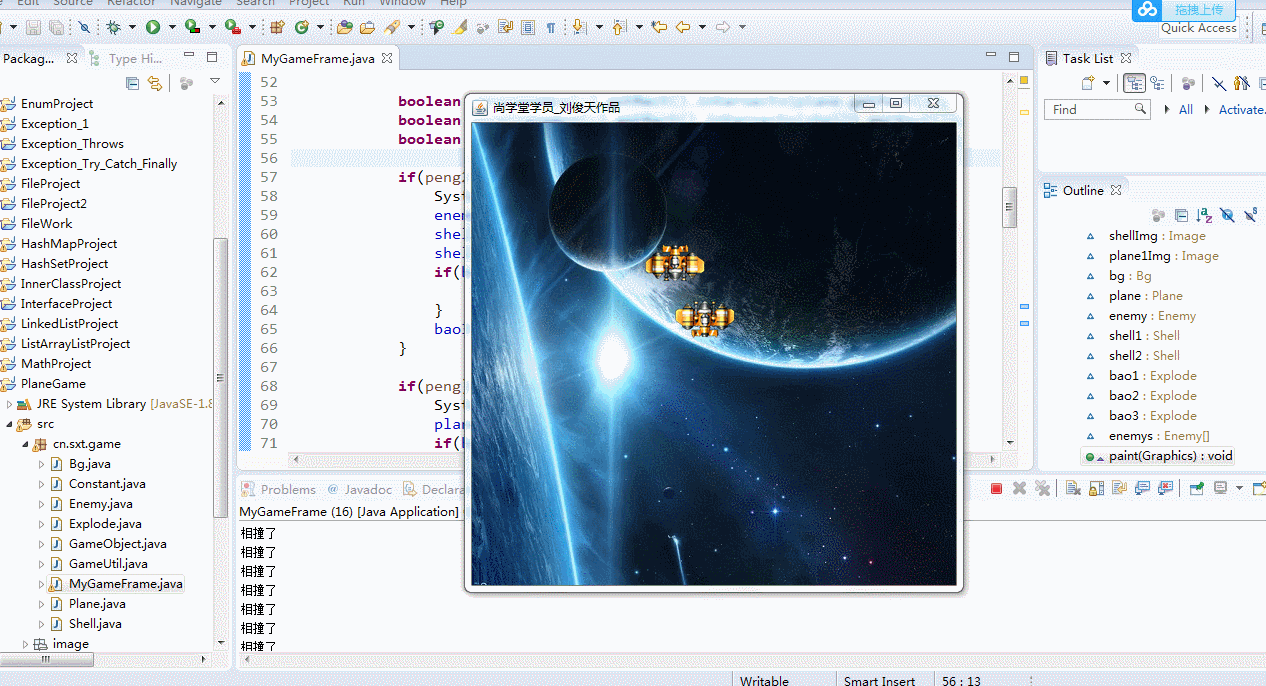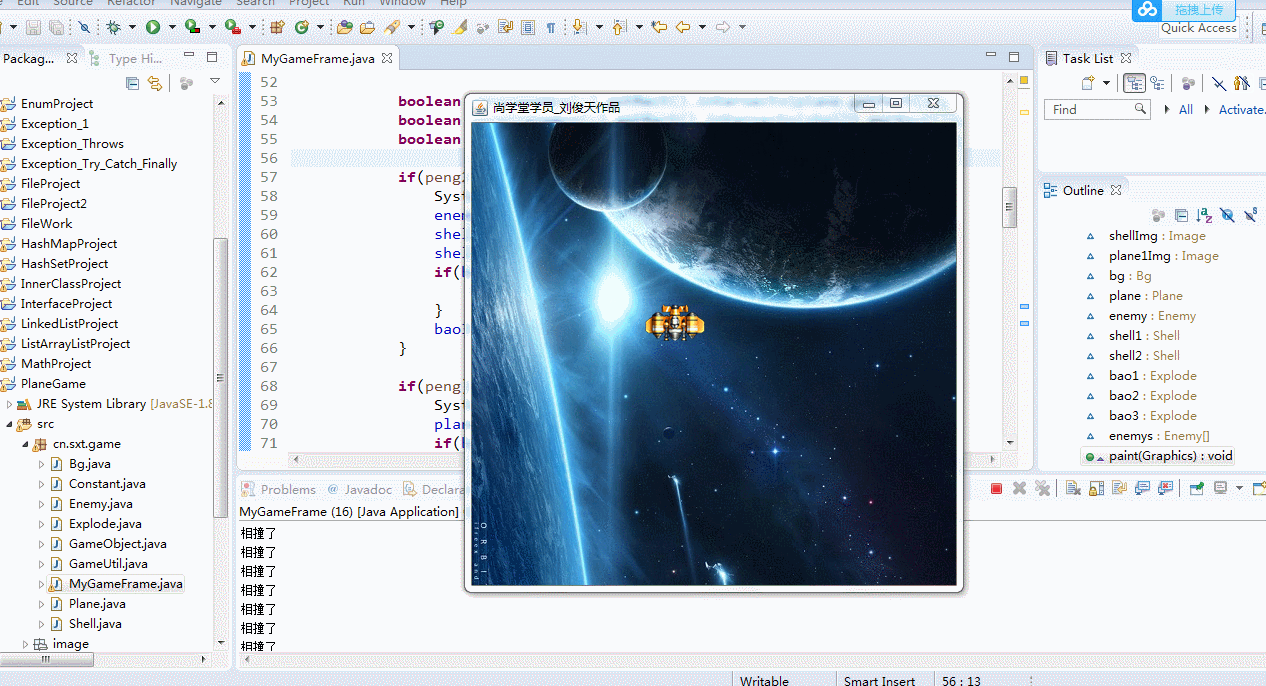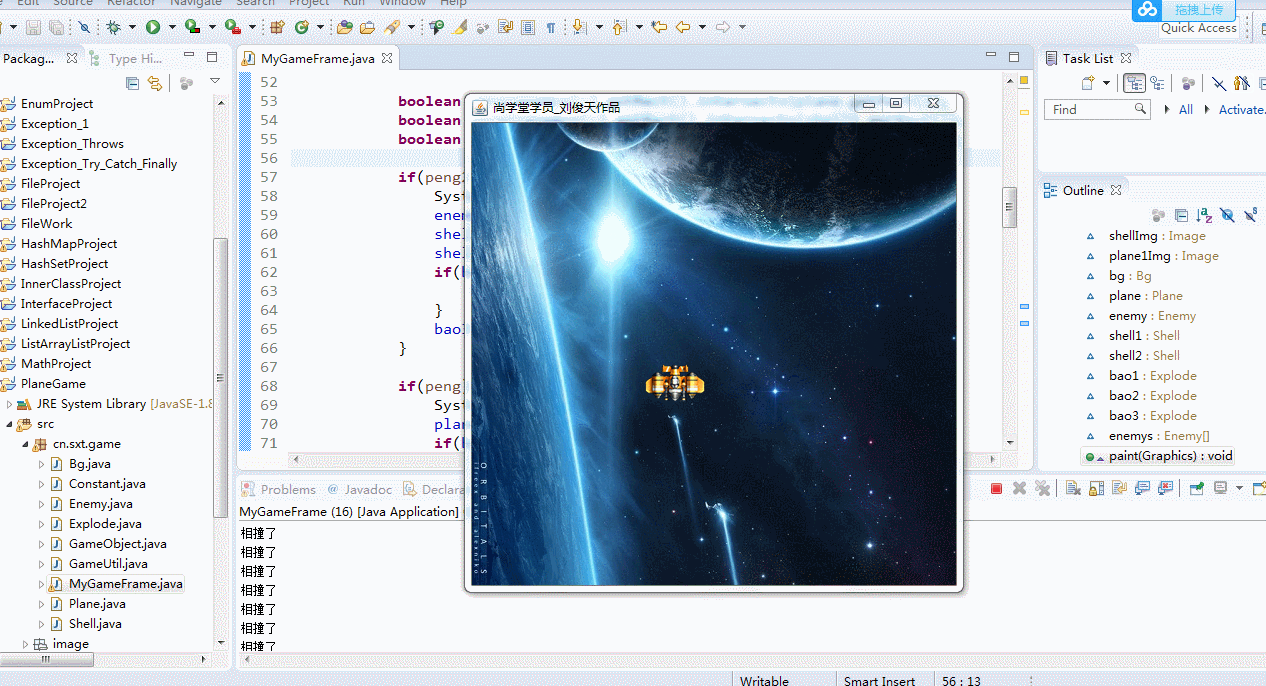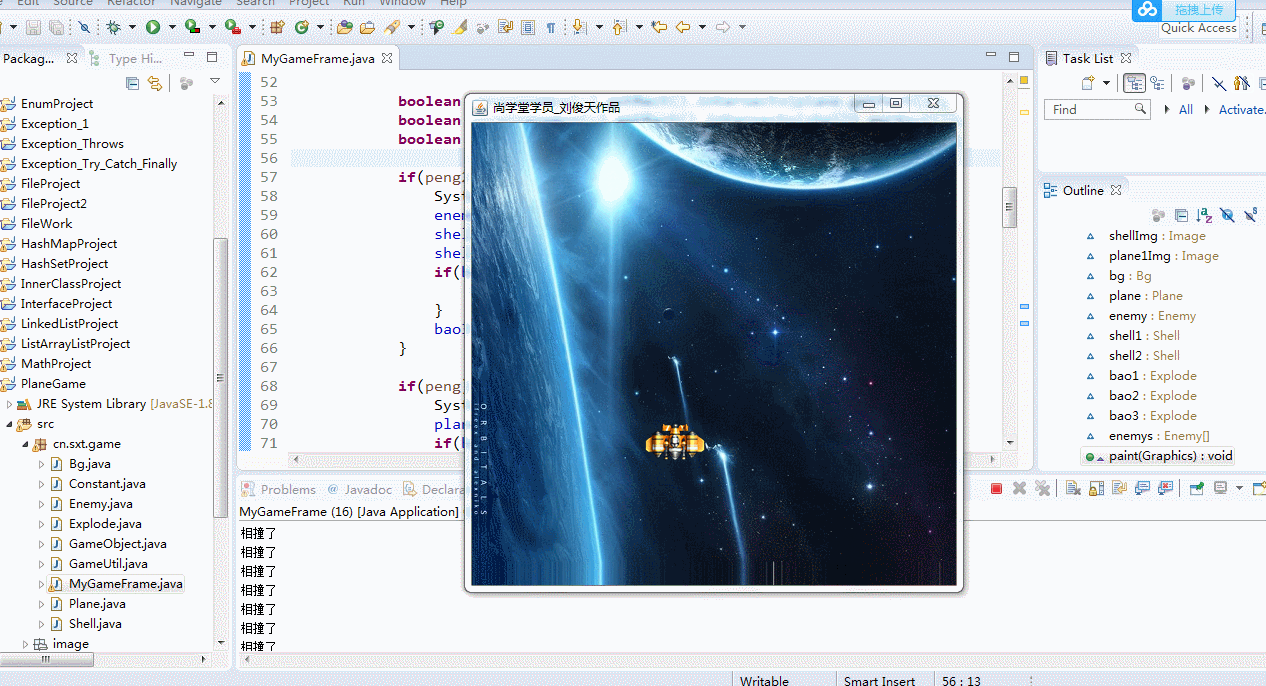
1、物体相撞消失后为何还会一直相撞?
问题.gif
//画出所有敌机 for(int i=0;i<enemys.length;i++) { enemys[i].drawSelf(g); //画敌机 boolean peng=enemys[i].getRect().intersects(plane.getRect()); boolean peng2=enemys[i].getRect().intersects(shell1.getRect()); boolean peng3=enemys[i].getRect().intersects(shell2.getRect()); if(peng2 || peng3) { System.out.println("相撞了"); enemys[i].live=false; shell1.live=false; shell2.live=false; if(bao3==null) { bao3=new Explode(enemys[i].x,enemys[i].y); } bao3.draw(g); } if(peng) { System.out.println("相撞了"); plane.live=false; if(bao1==null) { bao1=new Explode(plane.x,plane.y); } bao1.draw(g); } } if(plane.live) { shell1.drawSelf(g); //画炮弹 shell2.drawSelf(g); } }
怎么一直失败啊,我输入python -m pip install --upgrade pip 还是不能解决
document 没反应。老师请问我哪错了?
能不能在创建表之后就把所有的非唯一性的列设为索引
老师,这个是多表链接也是可以用内连接。那么当是多个表大于两个的时候,这个表名的位置应该怎么处理啊?就是什么样的表在join之前,什么样的在join之后?
我懂了
没事了
为什么“家电”跑到上面去了,咋办
老师我代码一样防火墙也关了结果输出还是这
老师,请问是2019.3.4版本的IDea不可以吗
我通过官网搭建项目时,JavaBoot都是高版本不是跟老师一样的版本
我该怎么解决呢
非常抱歉给您带来不好的体验!为了更深入的了解您的学习情况以及遇到的问题,您可以直接拨打投诉热线:
我们将在第一时间处理好您的问题!
关于
课程分类
百战程序员微信公众号
百战程序员微信小程序
©2014-2025百战汇智(北京)科技有限公司 All Rights Reserved 北京亦庄经济开发区科创十四街 赛蒂国际工业园网站维护:百战汇智(北京)科技有限公司 京公网安备 11011402011233号 京ICP备18060230号-3 营业执照 经营许可证:京B2-20212637









 老师,请问是2019.3.4版本的IDea不可以吗
老师,请问是2019.3.4版本的IDea不可以吗

{kind=link}