老师这几个章节怎么没有练习啊那怎么巩固新学的知识啊
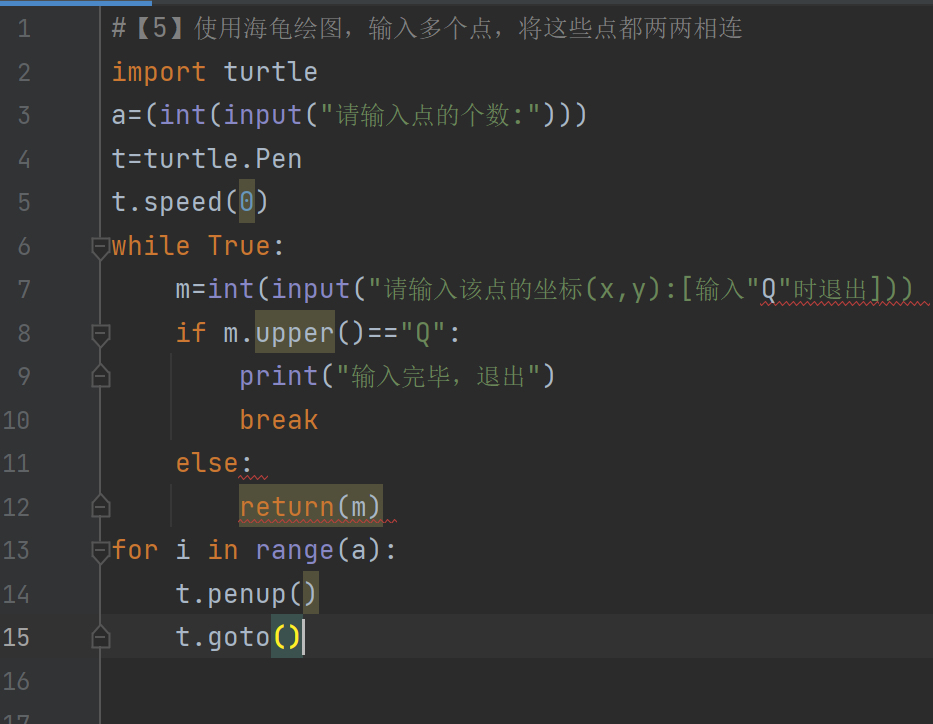
#【5】使用海龟绘图,输入多个点,将这些点都两两相连 import turtle a=(int(input("请输入点的个数:"))) t=turtle.Pen t.speed(0) while True: m=int(input("请输入该点的坐标(x,y):[输入"Q"时退出])) if m.upper()=="Q": print("输入完毕,退出") break else: return(m) for i in range(a): t.penup() t.goto()
老师,这个实操作业我真的不知道怎么写了,没有思路,看了别人的作业越看越模糊,大家的方法都不一样,感觉还是直接问您比较好
这是什么情况
为什么我这个日期都不是一天呀,都快了20个小时,是时区的问题吗,但是我的时区是调的上海呀,这个日期不对应可以吗
不明白为什么,我把47行多行注释了,可是运行之后报错的空指针还是指向了这一行
a = [x*2 for x in range(100) if x%9==0] #通过 if 过滤元素
老师这个生成列表的方式,是先判断x 被9整数,然后乘以2加入列表,还是说是先x乘以2在判断被9整除加入列表
这咋解决
请问老师,我这个错是为什么呀??
只显示一个分号的错误。
老师,我一加完配置就已经生效了。都不用加临时有效,不懂为啥。
score =int(input("请输入一个0~100的分数:"))grade = ""if score>100 or score<0: print(input("输入错误!请重新输入一个0~100的分数:"))elif score<60: grade = "E"elif score<70: grade = "D"elif score<80: grade = "C"elif score<90: grade = "B"else: grade = "A"print("分数是{0},等级是{1}".format(score,grade))老师 最后一句的输入怎么错了
老师的凹凸定义是不是不对啊,y=x^2不是凹函数吗
商城项目.zip
为什么“家电”跑到上面去了,咋办
老师好,今天在看这个视频后,想要自己去分析一下Object类,任何一个类的超类。发现 他没有构造函数。这Object源码中没有写构造函数,是编译器自动加了构造函数,是吗?可以讲解一下这里吗?
老师为什么,运行debug是这样的。好像是跳到源码了
from django.http import JsonResponse from rest_framework.parsers import JSONParser from rest_app.models import Student from rest_app.serializers import StudentSerializer from django.views.decorators.csrf import csrf_exempt #不进行csrf检测 @csrf_exempt def students(request): #GET请求(获取) if request.method == 'GET': #获取所有的student数据 student_li = Student.objects.all() #进行序列化,many=True serializer = StudentSerializer(student_li,many=True) #返回一个json格式的响应到客户端 #safe为True,必须传入字典。但是前面传入的是列表,只要是字典以外的格式都要将safe设为false #没有指定响应状态吗,默认是200 return JsonResponse(serializer.data,safe=False) #POST请求(新增) elif request.method == 'POST': #使用JSONParser将request的主题内容进行反序列化 data = JSONParser().parse(request) #将上一部的字典数据传入到序列化中 serializer = StudentSerializer(data=data) #进行验证 if serializer.is_valid(): #保存数据到数据库 serializer.save() #返回201状态码 和 辛堡村的数据库的数据 201:新增 return JsonResponse(serializer.data,status=201) #数据验证失败,则返回400状态码 和 序列化类的所有错误信息 return JsonResponse(serializer.errors,status=400)
老师 我的代码何老师的一样,为什么 不管是 在Terminal中还是 在程序跑起来,都会报一个错误,报错代码如下
我尝试调整版本问题 依据是如下图
不管怎么样调整还是不对 ,麻烦老师帮忙解答下。已经换了两台电脑进行检测了
非常抱歉给您带来不好的体验!为了更深入的了解您的学习情况以及遇到的问题,您可以直接拨打投诉热线:
我们将在第一时间处理好您的问题!
关于
课程分类
百战程序员微信公众号
百战程序员微信小程序
©2014-2025百战汇智(北京)科技有限公司 All Rights Reserved 北京亦庄经济开发区科创十四街 赛蒂国际工业园网站维护:百战汇智(北京)科技有限公司 京公网安备 11011402011233号 京ICP备18060230号-3 营业执照 经营许可证:京B2-20212637







 这咋解决
这咋解决





